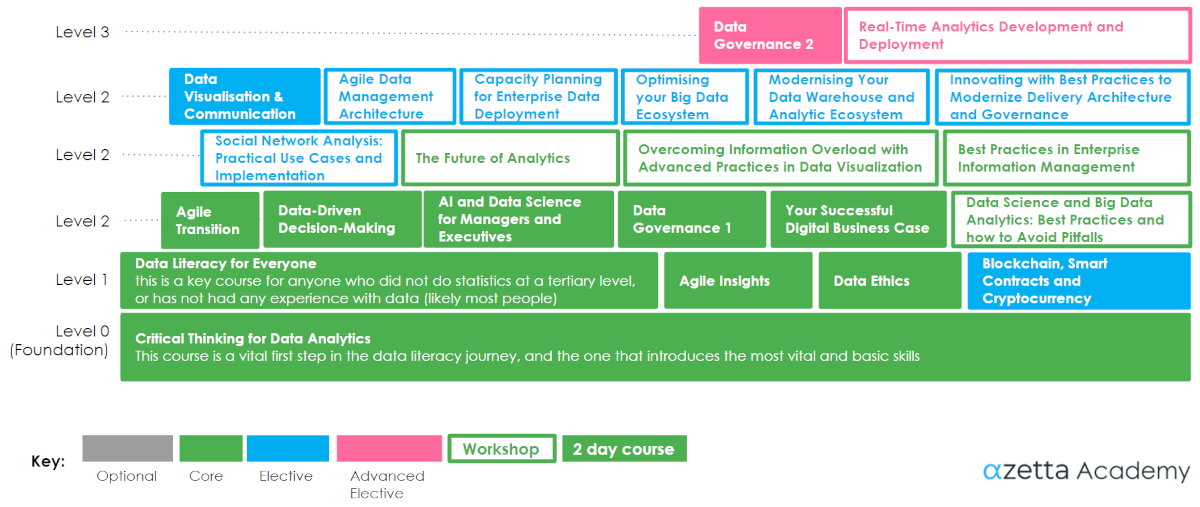
Executive Curriculum for Data Analytics
Our Executive Curriculum is perfect for CIOs, CEOs and other senior managers. It is the minimal “data literacy” curriculum for middle and upper managers who don’t want to get too close to the actual data science work, but need to understand what it is all about, how it can benefit them, and how they might manage it.
Executives and senior managers are time poor – so our 1-2 day courses are a perfect fit for them to learn the underlying concepts and how they can impact on the creation of business value. Our online formats are often more flexible, delivered in part days.
AlphaZetta’s workshops and courses are like none other offered in universities, online or by private providers. They are also as much a compressed mentoring experience as they are content delivery; they are not easy for an average trainer to replicate.
Contact us today to discuss how our Executive Curriculum could be tailored for your organisation.
{kind=link}
*Contact us for schedule and course details
Managers may also attend specialised courses such as Fraud And Anomaly Detection or Text and Language Analytics if these are relevant to their work.
Data Visualisation and Communication
This course prepares data analytics professionals to communicate analytics results to business audiences, in a business context while being mindful of the skills, incentives, priorities and psychology of the audience. It also equips analysts [...]
Critical Thinking for Data Analytics
This course is a vital first step in the data literacy journey, and the one that introduces the most vital and basic skills of the effective 21st century professional or leader. Working with data is not just about manipulating software tools : it is first and foremost about effective reasoning, using all available information. As such, this course loads the key “software” into the most vital hardware of the business - the human professional, enabling them to reason effectively with data, and thus realise the value that data analytics promises, deriving more reliable and correct insights and making better decisions.
Fundamentals of AI, Machine Learning, Data Science and Predictive Analytics
This course is an intuitive, hands-on introduction to ai, data science and machine learning, it's your artificial intelligence 101. The training focuses on fundamentals and key skills, leaving you with a deep understanding of the core concepts of ai and data science and even some of the more advanced tools used in the field. The course does not involve coding, or require any coding knowledge or experience. As our leading course, it has transformed the artificial intelligence (AI), machine learning (ML) and data science practice of the many managers, sponsors, key stakeholders, entrepreneurs and beginning data analytics and data science practitioners who have attended it.
AI and Data Science for Managers and Executives
Improve your project’s chance of success by avoiding common failures in AI and data science projects. This one-day workshop is aimed at current or aspiring leaders and managers of AI / machine learning teams and functions. The focus of the course is on the key concepts that are required to avoid the most common and far too frequent failures in AI projects and initiatives.
Data Science and Big Data Analytics: Leveraging Best Practices and Avoiding Pitfalls
Data science is the key to business success in the information economy. This workshop will teach you about best practices in deploying a data science capability for your organisation. Technology is the easy part; the hard part is creating the right organisational and delivery framework in which data science can be successful in your organisation. We will discuss the necessary skill sets for a successful data scientist and the environment that will allow them to thrive. We will draw a strong distinction between “Data R&D” and “Data Product” capabilities within an enterprise and speak to the different skill sets, governance, and technologies needed across these areas. We will also explore the use of open data sets and open source software tools to enable best results from data science in large organisations. Advanced data visualisation will be described as a critical component of a big data analytics deployment strategy. We will also talk about the many pitfalls and how to avoid them.
Data Governance I
This two day course provides an informed, realistic and comprehensive foundation for establishing best practice data governance in your organisation. Suitable for every level from CDO to executive to data steward, this highly practical course will equip you with the tools and strategies needed to successfully create and implement a data governance strategy and roadmap.
Data Literacy for Everyone
This course is for workers and managers without a strong quantitative background. It introduces a range of skills and applications related to data literacy for digital transformations and critical thinking in such areas as forecasting, population measurement, set theory and logic, causal impact and attribution, scientific reasoning and the danger of cognitive biases. There are no prerequisites beyond high-school mathematics; this course has been designed to be approachable for everyone.
Data-Driven Decision-Making
The Data-Driven Decision-Making course is for executives and managers who want to leverage analytics to support their most vital decisions and enable better decision-making at the highest levels. It empowers senior executives with skills to make more effective use of data analytics. It covers contexts including strategic decision-making and shows attendees ways to use data to make better decisions. Attendees will learn how to receive, understand and make decisions from a range of analytics methods, including visualisation and dashboards. They will also be taught to work with analysts as effective customers.
Data Governance II
This one day course builds on the foundation of Data Governance I, and dives deeper into selected areas that are designed to provide the most practical and real-world applications of data governance. It includes the change management journey to the “data-driven” organisation, and implications of the necessity of model governance in the context of data science, AI/ML initiatives and RPA/IPA .
Best Practices in Enterprise Information Management
The effective management of enterprise information for analytics deployment requires best practices in the areas of people, processes, and technology. In this talk we will share both successful and unsuccessful practices in these areas. The scope of this workshop will involve five key areas of enterprise information management: (1) metadata management, (2) data quality management, (3) data security and privacy, (4) master data management, and (5) data integration.
Agile Insights
This course presents a process and methods for an agile analytics delivery. Agile Insights reflects the capabilities required by any organisation to develop insights from data and validate potential business value. Content presented describes the process, how it is executed and how it can be deployed as a standard process inside an organisation. The course will also share best practices, highlight potential tripwires to watch out for, as well as roles and resources required.
Overcoming Information Overload with Advanced Practices in Data Visualisation
In this workshop, we explore best practices in deriving insight from vast amounts of data using visualisation techniques. Examples from traditional data as well as an in-depth look at the underlying technologies for visualisation in support of geospatial analytics will be undertaken. We will examine visualisation for both strategic and operational BI.
Understand Blockchain, Smart Contracts and Cryptocurrency
Blockchain is one of the most disruptive and least understood technologies to emerge over the previous decade. This course gives participants an intuitive understanding of blockchain in both public and private contexts, allowing them to distinguish genuine use cases from hype. We explore public crypto-currencies, smart contracts and consortium chains, interspersing theory with case studies from areas such as financial markets, health care, trade finance, and supply chain. The course does not require a technical background.
The Future of Analytics
This full day workshop examines the trends in analytics deployment and developments in advanced technology. The implications of these technology developments for data foundation implementations will be discussed with examples in future architecture and deployment. This workshop presents best practices for deployment of a next generation data management implementation as the realization of analytic capability for mobile devices and consumer intelligence. We will also explore emerging trends related to big data analytics using content from Web 3.0 applications and other non-traditional data sources such as sensors and rich media.
Innovating with Best Practices to Modernise Delivery Architecture and Governance
Organisations often struggle with the conflicting goals of both delivering production reporting with high reliability while at the same time creating new value propositions from their data assets. Gartner has observed that organizations that focus only on mode one (predictable) deployment of analytics in the construction of reliable, stable, and high-performance capabilities will very often lag the marketplace in delivering competitive insights because the domain is moving too fast for traditional SDLC methodologies. Explorative analytics requires a very different model for identifying analytic opportunities, managing teams, and deploying into production. Rapid progress in the areas of machine learning and artificial intelligence exacerbates the need for bi-modal deployment of analytics. In this workshop we will describe best practices in both architecture and governance necessary to modernise an enterprise to enable participation in the digital economy.
Modernising Your Data Warehouse and Analytic Ecosystem
This full-day workshop examines the emergence of new trends in data warehouse implementation and the deployment of analytic ecosystems. We will discuss new platform technologies such as columnar databases, in-memory computing, and cloud-based infrastructure deployment. We will also examine the concept of a “logical” data warehouse – including and ecosystem of both commercial and open source technologies. Real-time analytics and in-database analytics will also be covered. The implications of these developments for deployment of analytic capabilities will be discussed with examples in future architecture and implementation. This workshop also presents best practices for deployment of next generation analytics using AI and machine learning.
Optimising Your Big Data Ecosystem
Big Data exploitation has the potential to revolutionise the analytic value proposition for organisations that are able to successfully harness these capabilities. However, the architectural components necessary for success in Big Data analytics are different than those used in traditional data warehousing. This workshop will provide a framework for Big Data exploitation along with recommendations for architectural deployment of Big Data solutions.
Agile Data Management Architecture
This full-day workshop examines the trends in analytic technologies, methodologies, and use cases. The implications of these developments for deployment of analytic capabilities will be discussed with examples in future architecture and implementation. This workshop also presents best practices for deployment of next generation analytics.
Social Network Analysis: Practical Use Cases and Implementation
Social networking via Web 2.0 applications such as LinkedIn and Facebook has created huge interest in understanding the connections between individuals to predict patterns of churn, influencers related to early adoption of new products and services, successful pricing strategies for certain kinds of services, and customer segmentation. We will explain how to use these advanced analytic techniques with mini case studies across a wide range of industries including telecommunications, financial services, health care, retailing, and government agencies.
Capacity Planning for Enterprise Data Deployment
This workshop describes a framework for capacity planning in an enterprise data environment. We will propose a model for defining service level agreements (SLAs) and then using these SLAs to drive the capacity planning and configuration for enterprise data solutions. Guidelines will be provided for capacity planning in a mixed workload environment involving both strategic and tactical decision support. Performance implications related to technology trends in multi-core CPU deployment, large memory deployment, and high density disk drives will be described. In addition, the capacity planning implications for different approaches for data acquisition will be considered.
Real-Time Analytics Development and Deployment
Real-time analytics is rapidly changing the landscape for deployment of decision support capability. The challenges of supporting extreme service levels in the areas of performance, availability, and data freshness demand new methods for data warehouse construction. Particular attention is paid to architectural topologies for successful implementation and the role of frameworks for Microservices deployment. In this workshop we will discuss evolution of data warehousing technology and new methods for meeting the associated service levels with each stage of evolution.