{kind=link}
| Courses – 2 days | Courses – 1 day |
|---|---|
Core
Elective | Core |
*Contact us for schedule and course details.
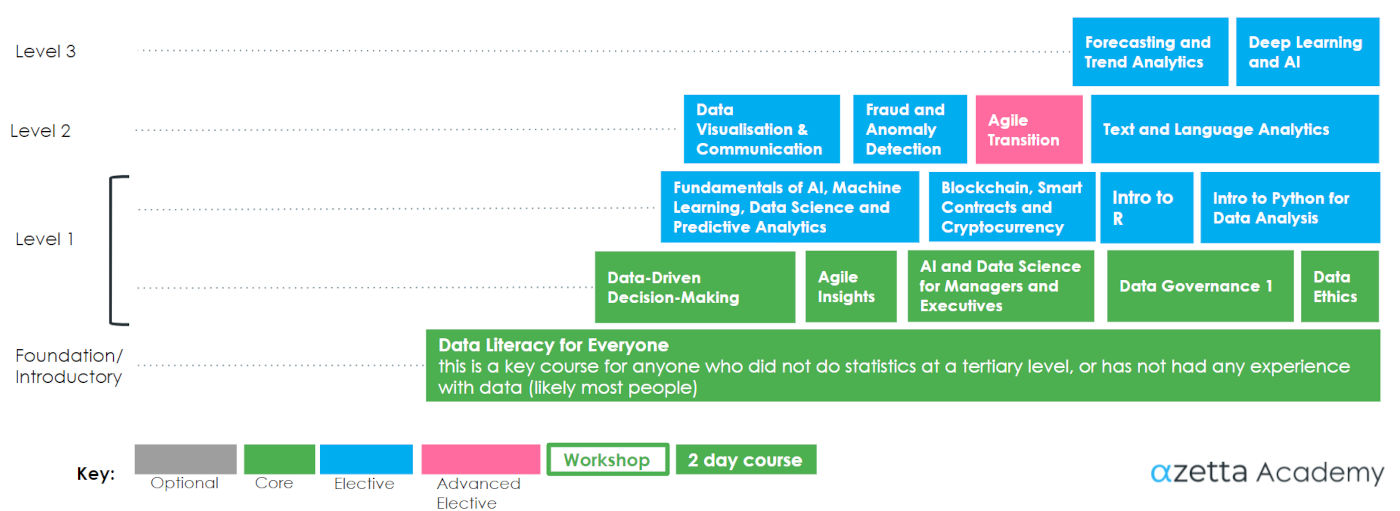
Fundamentals of AI, Machine Learning, Data Science and Predictive Analytics
This course is an intuitive, hands-on introduction to ai, data science and machine learning, it's your artificial intelligence 101. The training focuses on fundamentals and key skills, leaving you with a deep understanding of the core concepts of ai and data science and even some of the more advanced tools used in the field. The course does not involve coding, or require any coding knowledge or experience. As our leading course, it has transformed the artificial intelligence (AI), machine learning (ML) and data science practice of the many managers, sponsors, key stakeholders, entrepreneurs and beginning data analytics and data science practitioners who have attended it.
AI and Data Science for Managers and Executives
Improve your project’s chance of success by avoiding common failures in AI and data science projects. This one-day workshop is aimed at current or aspiring leaders and managers of AI / machine learning teams and functions. The focus of the course is on the key concepts that are required to avoid the most common and far too frequent failures in AI projects and initiatives.
Data Governance I
This two day course provides an informed, realistic and comprehensive foundation for establishing best practice data governance in your organisation. Suitable for every level from CDO to executive to data steward, this highly practical course will equip you with the tools and strategies needed to successfully create and implement a data governance strategy and roadmap.
Data Literacy for Everyone
This course is for workers and managers without a strong quantitative background. It introduces a range of skills and applications related to data literacy for digital transformations and critical thinking in such areas as forecasting, population measurement, set theory and logic, causal impact and attribution, scientific reasoning and the danger of cognitive biases. There are no prerequisites beyond high-school mathematics; this course has been designed to be approachable for everyone.
Data-Driven Decision-Making
The Data-Driven Decision-Making course is for executives and managers who want to leverage analytics to support their most vital decisions and enable better decision-making at the highest levels. It empowers senior executives with skills to make more effective use of data analytics. It covers contexts including strategic decision-making and shows attendees ways to use data to make better decisions. Attendees will learn how to receive, understand and make decisions from a range of analytics methods, including visualisation and dashboards. They will also be taught to work with analysts as effective customers.
Data Governance II
This one day course builds on the foundation of Data Governance I, and dives deeper into selected areas that are designed to provide the most practical and real-world applications of data governance. It includes the change management journey to the “data-driven” organisation, and implications of the necessity of model governance in the context of data science, AI/ML initiatives and RPA/IPA .
Data Transformation and Analysis Using Apache Spark
With big data expert and author Jeffrey Aven. Learn how to develop applications using Apache Spark. The first module in the “Big Data Development Using Apache Spark” series, this course provides a detailed overview of the spark runtime and application architecture, processing patterns, functional programming using Python, fundamental API concepts, basic programming skills and deep dives into additional constructs including broadcast variables, accumulators, and storage and lineage options. Attendees will learn to understand the Apache Spark framework and runtime architecture, fundamentals of programming for Spark, gain mastery of basic transformations, actions, and operations, and be prepared for advanced topics in Spark including streaming and machine learning.
Agile Insights
This course presents a process and methods for an agile analytics delivery. Agile Insights reflects the capabilities required by any organisation to develop insights from data and validate potential business value. Content presented describes the process, how it is executed and how it can be deployed as a standard process inside an organisation. The course will also share best practices, highlight potential tripwires to watch out for, as well as roles and resources required.
Agile Transition
This course describes the cultural and organisational aspects required for an organisation on the digital transformation path. A healthy corporate culture around data awareness is imperative to leverage the potential and value of data to the benefit of a company's business model. The organisation needs to reflect the culture and reward those who add value to a corporation by using data and analytics. Content presented explains personality and skill identification, how to prototype an agile analytics organisation and describe how to validate change capabilities, close gaps and execute a transition strategy.
Understand Blockchain, Smart Contracts and Cryptocurrency
Blockchain is one of the most disruptive and least understood technologies to emerge over the previous decade. This course gives participants an intuitive understanding of blockchain in both public and private contexts, allowing them to distinguish genuine use cases from hype. We explore public crypto-currencies, smart contracts and consortium chains, interspersing theory with case studies from areas such as financial markets, health care, trade finance, and supply chain. The course does not require a technical background.